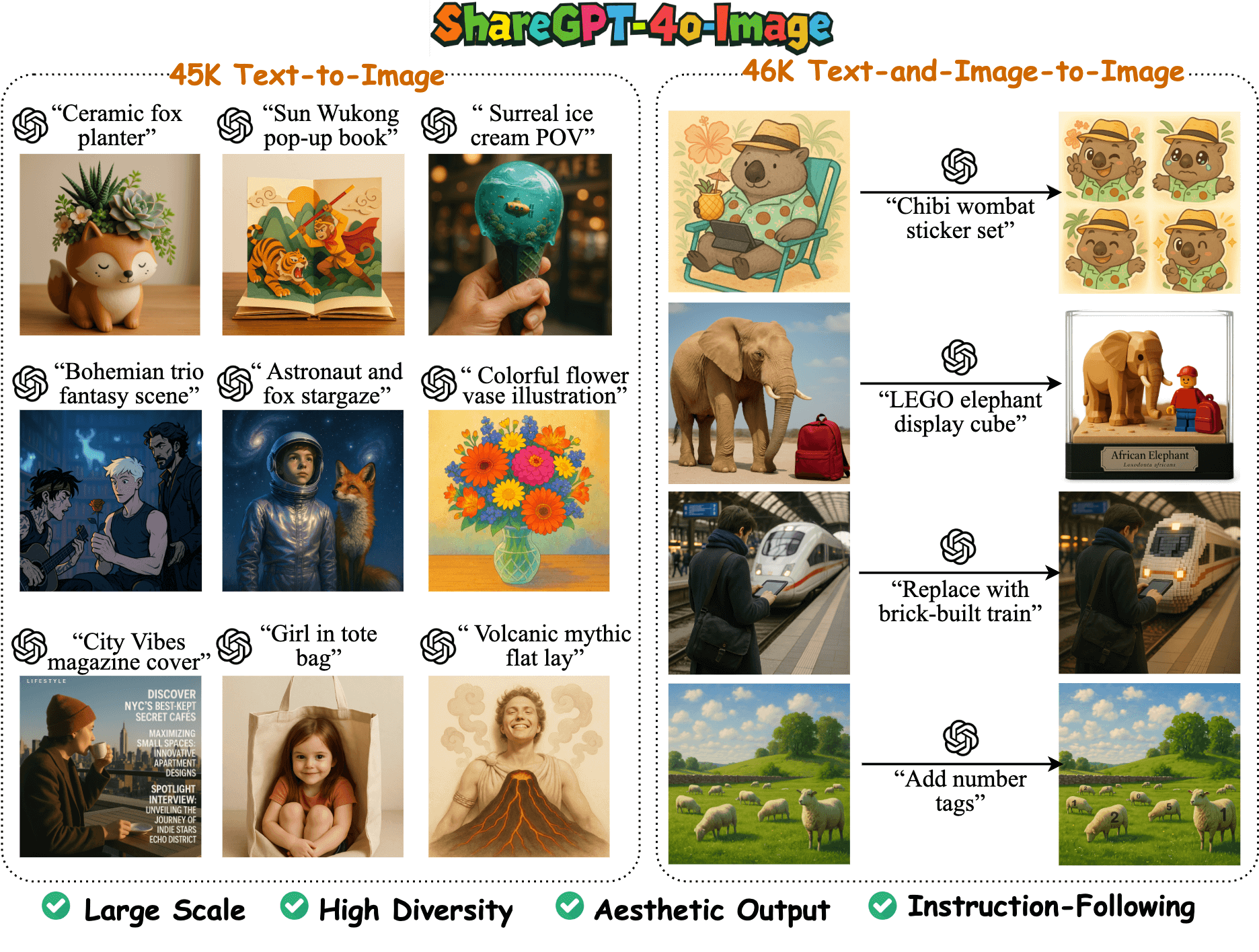
ShareGPT-4o-Image
综合介绍
ShareGPT-4o-Image 是一个开源项目,它提供了一个大规模、高质量的图像数据集,以及一个在此基础上训练出来的多模态语言模型 Janus-4o。这个项目的主要目标是,让开发者和研究者能够利用这些资源,开发出能理解文本、理解图像,并根据这些信息生成新图像的人工智能模型。数据集里的所有内容都来源于 GPT-4o 模型,包含了超过9万个样本,覆盖了“用文字生成图片”(文生图)和“用文字和参考图片共同生成新图片”(图生图)两种情况。 项目中的 Janus-4o 模型在 ShareGPT-4o-Image 数据集上经过微调,虽然在整体性能上与顶级的 GPT-4o 还有差距,但它显著提升了开源模型在图像生成和编辑方面的能力,为相关领域的研究和应用提供了有力的支持。
功能列表
- ShareGPT-4o-Image 数据集: 提供了一个包含92,256个由GPT-4o生成的样本,是目前首个此类数据集。
- 文本到图像 (Text-to-Image): 包含45,717个样本,用于根据文本描述直接生成图像。
- 文本和图像到图像 (Text-and-Image-to-Image): 包含46,539个样本,用于根据现有图像和文本指令进行编辑和修改。
- Janus-4o 模型: 一个基于Janus-Pro微调的多模态大语言模型,能同时处理和生成文本与图像。
- 文本到图像生成: 能够理解复杂的文本描述,并生成与之匹配的高质量图像。
- 文本和图像到图像生成: 支持用户上传一张图片,并用文字指令对其进行修改,例如改变场景风格、替换物体等。
- 开源代码: 项目提供了完整的模型推理代码,包括环境安装、模型加载和运行示例,方便开发者快速上手。
使用帮助
下面将详细介绍如何安装和使用 ShareGPT-4o-Image 项目中的 Janus-4o 模型来进行图像生成。整个过程需要一些基础的编程知识,并需要一台配备有NVIDIA GPU的电脑。
第一步:环境准备与安装
在开始之前,你需要确保你的电脑上安装了Git(用于克隆代码仓库)和Python(建议使用3.8以上版本)。然后,你需要安装项目的依赖包。
- 克隆Janus仓库首先,打开你的终端(在Windows上是命令提示符或PowerShell,在macOS或Linux上是Terminal),然后使用
git命令克隆Janus项目的代码。这个仓库包含了运行Janus-4o模型所需的核心代码。git clone https://github.com/deepseek-ai/Janus.git - 进入项目目录克隆完成后,使用
cd命令进入刚刚下载好的Janus文件夹。cd Janus - 安装核心依赖在
Janus目录中,使用pip工具安装项目运行所必需的软件包。-e .命令会以“可编辑”模式安装,这意味着你对代码的修改会立刻生效,方便开发和调试。pip install -e . - 安装Gradio演示界面(可选)如果你想通过一个简单的网页界面来与模型交互,可以安装Gradio相关的依赖。
pip install -e .[gradio]
第二步:运行模型进行推理
安装完成后,你可以选择两种方式来使用模型:一种是通过Gradio提供的图形化界面,另一种是直接运行Python脚本。
方式A:通过Gradio本地网页运行(推荐新手)
这是一种最简单直观的方式。在终端中运行以下命令:
python demo/app_janus4o.py
该命令会启动一个本地的Web服务器。启动成功后,终端会显示一个类似 http://127.0.0.1:7860 的网址。你可以在浏览器中打开这个地址,就能看到一个操作界面。你可以在界面上输入文本提示词,或者上传图片并附上修改指令,然后点击生成按钮,等待模型输出结果。
方式B:通过Python脚本进行推理
对于开发者来说,直接在代码中调用模型会更加灵活。项目提供了两种核心功能的调用方法:
1. 文本到图像生成 (Text-to-Image)
你需要创建一个Python脚本文件(例如 generate_image.py),然后将下面的代码复制进去。这段代码将加载模型,并根据你提供的文本提示词生成一张图片。
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
# --- 1. 加载模型和处理器 ---
# 定义模型路径,这里直接使用Hugging Face上的模型名称
model_path = "FreedomIntelligence/Janus-4o-7B"
# 加载处理器,它负责将文本和图像数据转换成模型可以理解的格式
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
# 加载Janus-4o模型,trust_remote_code=True是必须的,因为它会执行模型仓库中的自定义代码
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16 # 使用bfloat16以节省显存
)
# 将模型移动到GPU上并设置为评估模式
vl_gpt = vl_gpt.cuda().eval()
# --- 2. 定义生成函数 ---
def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5):
# 此处省略了GitHub仓库中完整的函数代码,实际使用时请直接从仓库的README复制
# 这里只展示核心调用逻辑
# ... 完整的生成函数代码 ...
pass # 假设这里是完整的函数实现
# --- 3. 运行生成任务 ---
# 定义你的文本提示词
prompt = "一位来自喀布尔的公主,穿着红白相间的传统服装,蓝眼睛,棕色头发,非常惊艳"
# 定义输出图片的文件路径
image_output_path = "./princess.png"
# 调用生成函数,parallel_size表示同时生成几张图片供选择
# 注意:你需要从GitHub仓库[1]中复制完整的 `text_to_image_generate` 函数定义才能运行
# text_to_image_generate(prompt, image_output_path, vl_chat_processor, vl_gpt, parallel_size=2)
print("请从GitHub仓库复制完整的生成函数来执行此脚本。")
请注意:上述代码只是一个框架,完整的text_to_image_generate函数实现比较长,需要从项目的GitHub页面直接复制。
2. 文本和图像到图像生成 (Text-and-Image-to-Image)
这个功能允许你对一张现有图片进行修改。你需要准备一张输入图片,并提供修改指令。
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from dataclasses import dataclass
# --- 1. 准备工作 ---
# 同样需要先加载模型和处理器,代码与上一个例子相同
model_path = "FreedomIntelligence/Janus-4o-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True, torch_dtype=torch.bfloat16
).cuda().eval()
# --- 2. 定义生成函数 ---
# 同样,完整的 `text_and_image_to_image_generate` 函数需要从GitHub仓库复制[1]
def text_and_image_to_image_generate(input_prompt, input_image_path, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5, cfg_weight2=5):
# ... 完整的生成函数代码 ...
pass # 假设这里是完整的函数实现
# --- 3. 运行生成任务 ---
# 准备一张输入图片,例如命名为 `test_input.png` 并放在代码同目录下
# 这里需要你手动准备一张图片
if not os.path.exists("test_input.png"):
print("错误:请在当前目录下准备一张名为 'test_input.png' 的图片。")
else:
# 定义你的修改指令
prompt = "把这张图变成夜晚的场景"
# 定义输入和输出图片的路径
input_image_path = "./test_input.png"
image_output_path = "./test_output.png"
# 调用生成函数
# 注意:你需要从GitHub仓库[1]中复制完整的 `text_and_image_to_image_generate` 函数定义才能运行
# text_and_image_to_image_generate(prompt, input_image_path, image_output_path, vl_chat_processor, vl_gpt, parallel_size=2)
print("请从GitHub仓库复制完整的生成函数来执行此脚本。")
请注意:运行此脚本前,你需要在代码文件所在的目录放置一张名为test_input.png的图片作为输入。
应用场景
- 多模态模型研究对于AI领域的研究人员,ShareGPT-4o-Image数据集是宝贵的资源。 他们可以利用这个高质量、大规模且与GPT-4o对齐的数据集来训练、验证和改进自己的多模态模型,推动图像生成技术的发展。
- 内容创作与艺术设计艺术家、设计师和内容创作者可以使用Janus-4o模型快速将创意想法转化为视觉图像。无论是根据一句话描述生成全新的插画,还是对现有照片进行风格转换或内容修改,该工具都能提供强大的支持。
- 教育与学习对于学习人工智能和深度学习的学生来说,该项目是一个绝佳的实践案例。通过研究其代码和数据,学生可以深入理解多模态大模型的工作原理,并亲手实践图像生成任务。
- 定制化商业应用开发者可以将Janus-4o模型集成到自己的应用程序中,为用户提供智能图像生成和编辑服务。例如,在社交媒体应用中加入AI生成头像的功能,或是在电商平台中提供商品背景替换的服务。
QA
- ShareGPT-4o-Image、Janus-4o和GPT-4o之间有什么关系?ShareGPT-4o-Image 是一个数据集,里面的图片和文本描述都是用 OpenAI 的 GPT-4o 模型生成的。 Janus-4o 是一个开源的多模态模型,它使用了 ShareGPT-4o-Image 这个数据集进行了训练(微调),目的是学习 GPT-4o 的图像生成能力。所以,GPT-4o 是能力的来源,ShareGPT-4o-Image 是知识的载体(数据集),而 Janus-4o 是学习这些知识后的一个开源成果。
- Janus-4o 模型的图像生成效果能和 GPT-4o媲美吗?不能。根据项目作者的声明,尽管 Janus-4o 在使用 ShareGPT-4o-Image 数据集进行微调后,图像生成能力得到了显著提升,但其整体性能仍然落后于原版的 GPT-4o。 该项目的主要贡献在于为开源社区提供了一套高质量的数据和追赶先进模型能力的方法。
- 在哪里可以下载数据集和模型?数据集
ShareGPT-4o-Image和模型Janus-4o-7B都托管在开源社区 Hugging Face 上。你可以在项目的GitHub页面找到直接的链接,也可以在Hugging Face网站上搜索它们的名称进行下载。